Facilitating Ontology Development with Continuous Evaluation
Dejan Lavbič and Marjan Krisper. 2010. Facilitating Ontology Development with Continuous Evaluation, Informatica (INFOR), 21(4), pp. 533 - 552.
Abstract
In this paper we propose facilitating ontology development by constant evaluation of steps in the process of ontology development. Existing methodologies for ontology development are complex and they require technical knowledge that business users and developers don’t poses. By introducing ontology completeness indicator developer is guided throughout the development process and constantly aided by recommendations to progress to next step and improve the quality of ontology. In evaluating the ontology, several aspects are considered; from description, partition, consistency, redundancy and to anomaly. The applicability of the approach was demonstrated on Financial Instruments and Trading Strategies (FITS) ontology with comparison to other approaches.
Keywords
Ontology development methodology, ontology evaluation, ontology completeness, rapid ontology development, semantic web
1 Introduction
The adoption of Semantic Web technologies is less than expected and is mainly limited to academic environment. We are still waiting for wide adoption in industry. We could seek reasons for this in technologies itself and also in the process of development, because existence of verified approaches is a good indicator of maturity. As technologies are concerned there are numerous available for all aspects of Semantic Web applications; from languages for capturing the knowledge, persisting data, inferring new knowledge to querying for knowledge etc. In the methodological sense there is also a great variety of methodologies for ontology development available, as it will be further discussed in section 2, but the simplicity of using approaches for ontology construction is another issue. Current approaches in ontology development are technically very demanding and require long learning curve and are therefore inappropriate for developers with little technical skills and knowledge. In majority of existing approaches an additional role of knowledge engineer is required for mediation between actual knowledge that developers possess and ontology engineers who encode knowledge in one of the selected formalisms. The use of business rules management approach (Smaizys and Vasilecas 2009) seems like an appropriate way to simplification of development and use of ontologies in business applications. Besides simplifying the process of ontology creation we also have to focus on very important aspect of ontology completeness. The problem of error-free ontologies has been discussed in (Fahad and Quadir 2008; Porzel and Malaka 2004) and several types of errors were identified - inconsistency, incompleteness, redundancy, design anomalies etc. All of these problems have to already be addressed in the development process and not only after development has reached its final steps.
In this paper we propose a Rapid Ontology Development (ROD) approach where ontology evaluation is performed during the whole lifecycle of the development. The idea is to enable developers to rather focus on the content than the formalisms for encoding knowledge. Developer can therefore, based on recommendations, improve the ontology and eliminate the error or bad design. It is also a very important aspect that, before the application, the ontology is error free. Thus we define ROD model that introduces detail steps in ontology manipulation. The starting point was to improve existing approaches in a way of simplifying the process and give developer support throughout the lifecycle with continuous evaluation and not to conclude with developed ontology but enable the use of ontology in various scenarios. By doing that we try to achieve two things:
- guide developer through the process of ontology construction and
- improve the quality of developed ontology.
The remainder of the paper is structured as follows. In the following section 2 state of the art is presented with the review of existing methodologies for ontology development and approaches for ontology evaluation. After highlighting some drawbacks of current approaches section 3 presents the ROD approach. Short overview of the process and stages is given with the emphasis on ontology completeness indicator. The details of ontology evaluation and ontology completeness indicator are given in section 3.3, where all components (description, partition, redundancy and anomaly) that are evaluated are presented. In section 4 evaluation and discussion about the proposed approach according to the results obtained in the experiment of Financial Instruments and Trading Strategies (FITS) is presented. Finally in section 5 conclusions with future work are given.
3 Rapid Ontology Development
3.1 Introduction to ROD process
The process for ontology development ROD (Rapid Ontology Development) that we propose is based on existing approaches and methodologies (see section 2) but is enhanced with continuous ontology evaluation throughout the complete process. It is targeted at domain users that are not familiar with technical background of constructing ontologies.
Developers start with capturing concepts, mutual relations and expressions based on concepts and relations. This task can include reusing elements from various resources or defining them from scratch. When the model is defined, schematic part of ontology has to be binded to existing instances of that vocabulary. This includes data from relational databases, text file, other ontologies etc. The last step in bringing ontology into use is creating functional components for employment in other systems.
3.2 ROD stages
The ROD development process can be divided into the following stages: pre-development, development and post-development as depicted in Figure 3.1. Every stage delivers a specific output with the common goal of creating functional component based on ontology that can be used in several systems and scenarios. In pre-development stage the output is feasibility study that is used in subsequent stage development to construct essential model definition. The latter artifact represents the schema of problem domain that has to be coupled with instances from the real world. This is conducted in the last stage post-development which produces functional component for usage in various systems.
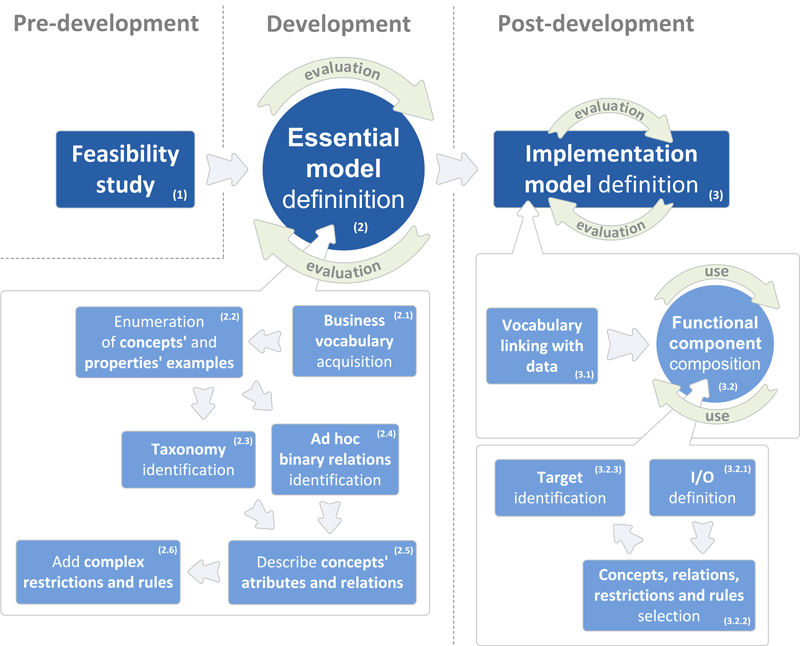
Figure 3.1: Process of rapid ontology development (ROD)
The role of constant evaluation as depicted in Figure 3.1 is to guide developer in progressing through steps of ROD process or it can be used independently of ROD process. In latter case, based on semantic review of ontology, enhancements for ontology improvement are available to the developer in a form of multiple actions of improvement, sorted by their impact. Besides actions and their impacts, detail explanation of action is also available (see Figure 3.2).

Figure 3.2: Display of ontology completeness (OC) results and improvement recommendations
In case of following ROD approach, while developer is in a certain step of the process, the OC measurement is adapted to that step by redefinition of weights (see Figure 3.5 for distribution of weights by ROD steps) for calculation (e.g., in Step 2.1 of ROD process where business vocabulary acquisition is performed, there is no need for semantic checks like instance redundancy, lazy concept existence or inverse property existence, but the emphasis is rather on description of TBox and RBox component and path existence between concepts).
When OC measurement reaches a threshold (e.g., \(80\%\)) developer can progress to the following step (see Figure 3.3). The adapted OC value for every phase is calculated on-the-fly and whenever a threshold value is crossed, a recommendation for progressing to next step is generated. This way developer is aided in progressing through steps of ROD process from business vocabulary acquisition to functional component composition.
In case that ontology already exists, with OC measure we can place the completeness of ontology in ROD process and start improving ontology in suggested phase of development (e.g., ontology has taxonomy already defined, so we can continue with step 2.4 where ad hoc binary relations identification takes place).
3.3 Ontology evaluation and ontology completeness indicator
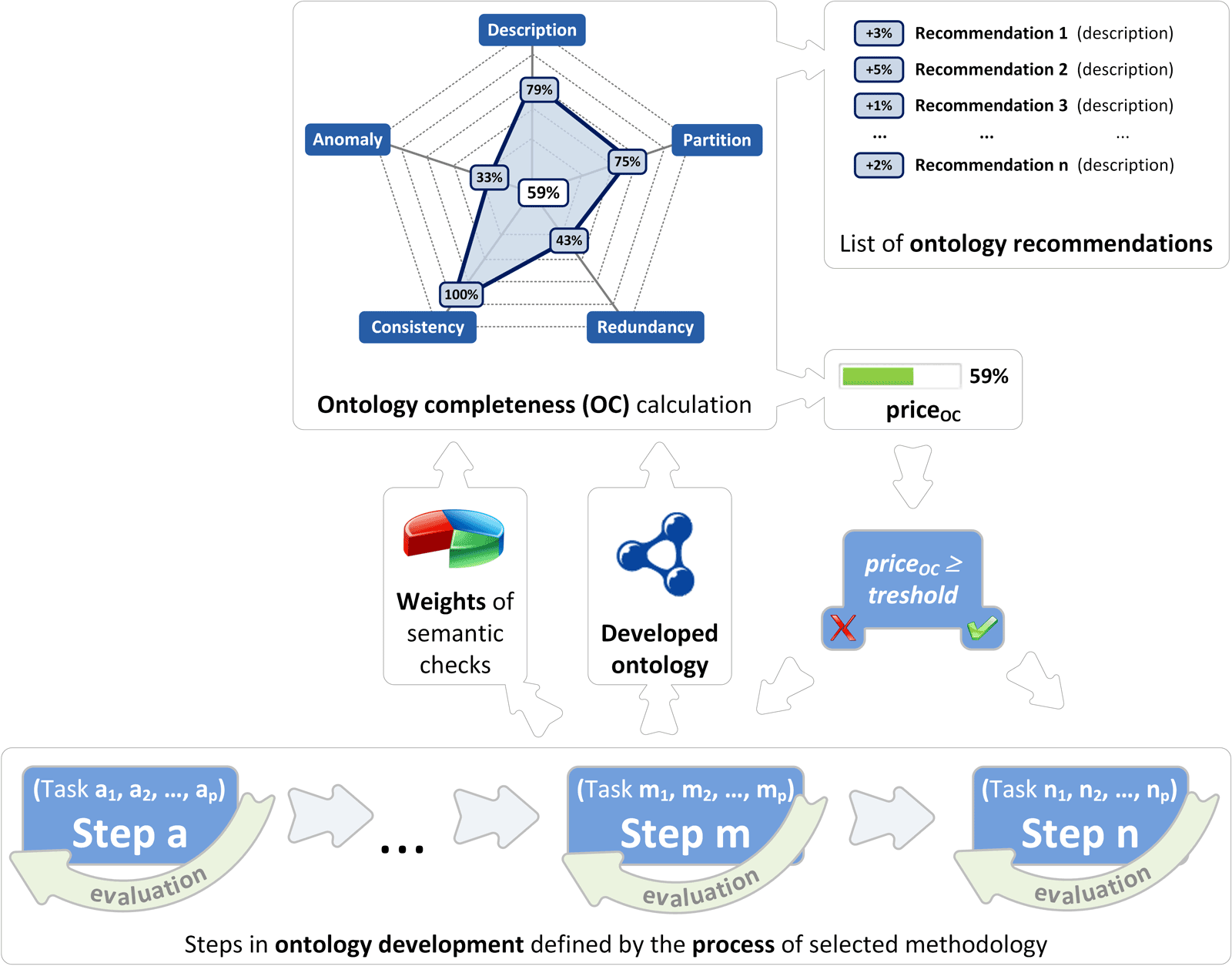
Figure 3.3: OC calculation
Ontology completeness (OC) indicator used for guiding developer in progressing through steps of ROD process and ensuring the required quality level of developed ontology is defined as
\[\begin{equation} OC = f \left( C, P, R, I \right) \in [0, 1] \tag{3.1} \end{equation}\]where \(C\) is set of concepts, \(P\) set of properties, \(R\) set of rules and \(I\) set of instances. Based on these input the output value in an interval \([0, 1]\) is calculated. The higher the value, more complete the ontology is. OC is weighted sum of semantic checks, while weights are being dynamically altered when traversing from one phase in ROD process to another. OC can be further defined as
\[\begin{equation} OC = \sum_{i=1}^{n} w_i^{'} \cdot leafCondition_i \tag{3.2} \end{equation}\]where \(n\) is the number of leaf conditions and \(leafCondition\) is leaf condition, where semantic check is executed. For relative weights and leaf condition calculation the following restrictions apply \(\sum_i w_i^{'} = 1\), \(\forall w_i^{'} \in [0, 1]\) and \(\forall leafCondition_i \in [0, 1]\). Relative weight \(w_i^{'}\) denotes global importance of \(leafCondition_i\) and is dependent on all weights from leaf to root concept.
The tree of conditions in OC calculation is depicted in Figure 3.4 and contains semantic checks that are executed against the ontology. The top level is divided into TBox, RBox and ABox components. Subsequent levels are then furthermore divided based on ontology error classification (Fahad and Quadir 2008). Aforementioned sublevels are description, partition, redundancy, consistency and anomaly.
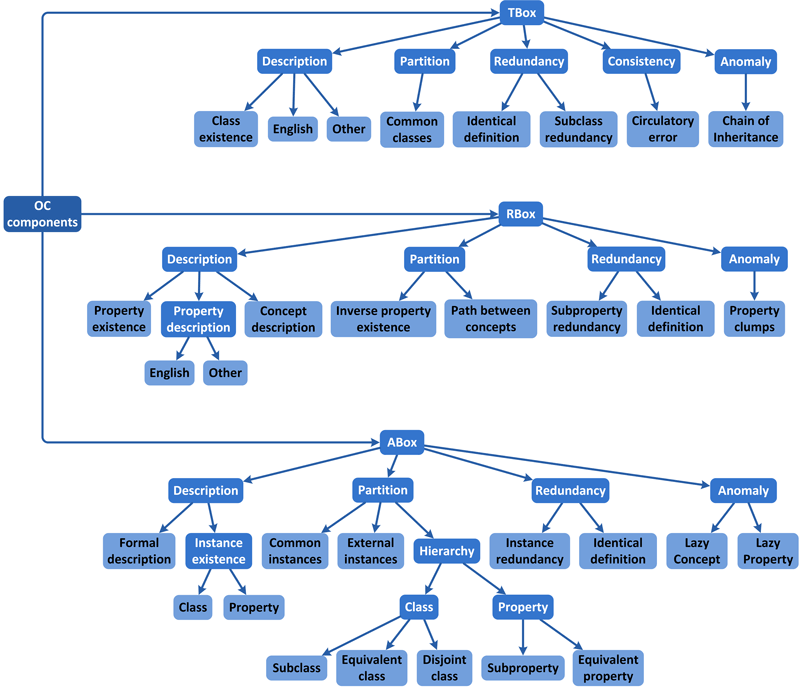
Figure 3.4: Ontology completeness (OC) tree of conditions, semantic checks and corresponding weights
This proposed structure can be easily adapted and altered for custom use. Leafs in the tree of OC calculation are implemented as semantic checks while all preceding elements are aggregation with appropriate weights. Algorithm for ontology completeness (OC) price is depicted in Definition 3.1, where \(X\) is condition and \(w = w(X, Y)\) is the weight between condition \(X\) and condition \(Y\).
Each leaf condition implements a semantic check against ontology and returns value \(leafCondition \in [0, 1]\).
Figure 3.5 depicts the distribution of OC components (description, partition, redundancy, consistency and anomaly) regarding individual phase in ROD process (see section 3.2). In first two phases 2.1 and 2.2 developer deals with business vocabulary identification and enumeration of concepts’ and properties’ examples. Evidently with aforementioned steps emphasis is on description of ontology, while partition is also taken into consideration. The importance of components description and partition is then in latter steps decreased but it still remains above average. In step 2.3 all other components are introduced (redundancy, consistency and anomaly), because developer is requested to define taxonomy of schematic part of ontology. While progressing to the latter steps of ROD process emphasis is on detail description of classes, properties and complex restriction and rules are also added. At this stage redundancy becomes more important. This trend of distributions of weights remains similarly balanced throughout the last steps 2.5 and 2.6 of development phase. In post-development phase when functional component composition is performed, ontology completeness calculation is mainly involved in redundancy, description and anomaly checking. The details about individual OC components are emphasized and presented in details in the following subsections.
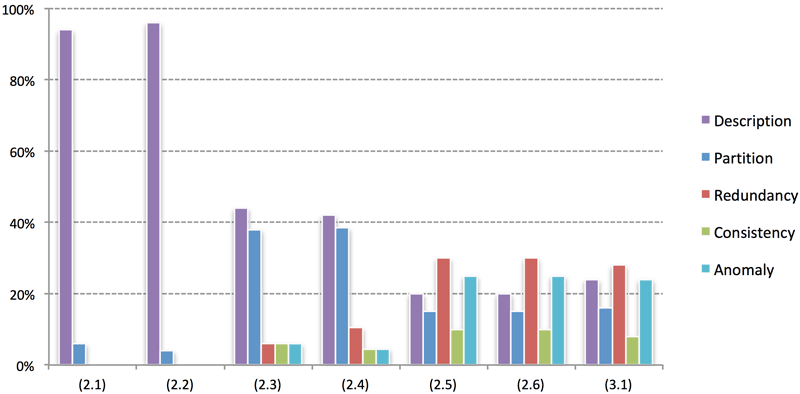
Figure 3.5: Impact of weights on OC sublevels in ROD process
3.3.1 Description
Description of ontology’s components is very important aspect mainly in early stages of ontology development. As OC calculation is concerned there are several components considered:
- existence of entities (classes and properties) and instances,
- (multiple) natural language descriptions of TBox and RBox components and
- formal description of concepts and instances.
The notion of existence of entities is very straightforward; if ontology doesn’t contain any entities than we have no artifacts to work with. Therefore the developer is by this metric encouraged to first define schematic part of ontology with classes and properties and then also to add elements of ABox component in a form of individuals.
Next aspect is natural language descriptions of entities. This element is despite of its simplicity one of the most important, due to ability to include these descriptions in further definition of complex axioms and rules (Vasilecas, Kalibatiene, and Guizzardi 2009). Following business rules approach (Vasilecas and Sosunovas 2008) it’s feasible to create templates for entering this data on-the-fly by employing this natural description of entities. Developer is encouraged to describe all entities (classes and properties) with natural language using readable labels (e.g., rdfs:label and rdfs:comment) that don’t add to the meaning of captured problem domain but greatly improves human readability of defined ontology. When constructing ontology it is always required to provide labels and description in English, but the use of other languages is also recommended to improve employment of ontology.
The last aspect of ontology description is formal description of TBox and ABox components that concerns concepts and instances. When describing classes with properties ontologists tend to forget defining domain and range values. This is evaluated for schematic part of ontology while for instances all required axioms are considered that are defined in TBox or ABox. Ontologists tend to leave out details of instances that are required (e.g., cardinality etc.).
3.3.2 Partition
Partition errors deal with omitting important axioms or information about the classification of concept and therefore reducing reasoning power and inferring mechanisms. In OC calculation several components are considered:
- common classes and instances,
- external instances of ABox component,
- connectivity of concepts of TBox component and
- hierarchy of entities.
The notion of common classes deals with the problem of defining a class that is a sub-class of classes that are disjoint. The solution is to check every class \(C_i\) if exist super-classes \(C_j\) and \(C_k\) that are disjoint. Similar is with common instances where situation can occur where instance is member of disjointing classes.
When decomposing classes in sub-class hierarchy it is often the case that super-class instance is not a member of any sub-class. In that case we deal with a problem of external instances. The solution is to check every class \(C_i\) if exist any instance that is a member of \(C_i\), but not a member of any class in set of sub-classes.
The aspect of connectivity of concepts deals with ontology as whole and therefore not allowing isolated parts that are mutually disconnected. The first semantic check deals with existence of inverse properties. If we want to contribute to full traversal among classes in ontology the fact that every object property has inverse property defined is very important.
The second semantic check deals with existence of path between concepts. Ontology is presented as undirected graph \(G = (V, E)\) and we try to identify maximum disconnected graphs.
The last aspect of ontology completeness as partition is concerned with hierarchy of entities. We introduce data oriented approach for definition of hierarchy of entities where technical knowledge from domain user is not required. This is based on requirement that for every class and property defined ontologist is requested to insert also few instances (see preliminary steps in ROD process introduced in section 3.2). After this requirement is met, set of competency questions are introduced to the domain user and the result are automatically defined hierarchy axioms (e.g., rdfs:subClassOf, owl:equivalentClass, owl:disjointWith, rdfs:subPropertyOf and rdfs:equivalentProperty).
The approach for disjoint class recommendation is depicted in Definition 3.2, while approach for other hierarchy axioms is analogous.
Using this approach of recommendation, domain users can define axioms in ontology without technical knowledge of ontology language, because with data driven approach (using instances) and competency questions the OC calculation indicator does that automatically.
Redundancy occurs when particular information is inferred more than once from entities and instances. When calculating OC we take into consideration following components:
- identical formal definition and
- redundancy in hierarchy of entities.
When considering identical formal definition, all components (TBox, RBox and ABox) have to be checked. For every entity or instance Ai all belonging axioms are considered. If set of axioms of entity or instance \(A_i\) is identical to set of axioms of entity or instance \(A_j\) and \(A_i \neq A_j\), then entities or instances \(A_i\) and \(A_j\) have identical formal definition. This signifies that \(A_i\) and \(A_j\) describe same concept under different names (synonyms).
Another common redundancy issue in ontologies is redundancy in hierarchy. This includes sub-class, sub-property and instance redundancy. Redundancy in hierarchy occurs when ontologist specifies classes, properties or instances that have hierarchy relations (rdfs:subClassOf, rdfs:subPropertyOf and owl:instanceOf) directly or indirectly.
3.3.3 Consistency
In consistency checking of developed ontology the emphasis is on finding circulatory errors in TBox component of ontology. Circulatory error occurs when a class is defined as a sub-class or super-class of itself at any level of hierarchy in the ontology. They can occur with distance \(0\), \(1\) or \(n\), depending upon the number of relations involved when traversing the concept down the hierarchy of concepts until we get the same from where we started traversal. The same also applies for properties. To evaluate the quality of ontology regarding circulatory errors the ontology is viewed as graph \(G = (V, E)\), where \(V\) is set of classes and \(E\) set of rdfs:subClassOf relations.
3.3.4 Anomaly
Design anomalies prohibit simplicity and maintainability of taxonomic structures within ontology. They don’t cause inaccurate reasoning about concepts, but point to problematic and badly designed areas in ontology. Identification and removal of these anomalies should be necessary for improving the usability and providing better maintainability of ontology. As OC calculation is concerned there are several components considered:
- chain of inheritance in TBox component,
- property clumps and
- lazy entities (classes and properties).
The notion of chain of inheritance is considered in class hierarchy, where developer can classify classes as rdfs:subClassOf other classes up to any level. When such hierarchy of inheritance is long enough and all classes have no appropriate descriptions in the hierarchy except inherited child, then ontology suffers from chain of inheritance. The algorithm for finding and eliminating chains of inheritance is depicted in Definition 3.3.
The next aspect in design anomalies is property clumps. This problem occurs when ontologists badly design ontology by using repeated groups of properties in different class definitions. These groups should be replaced by an abstract concept composing those properties in all class definitions where this clump is used. To identify property clumps the following approach depicted in Definition 3.4 is used.
The last aspect of design anomalies is lazy entities, which is a leaf class or property in the taxonomy that never appears in the application and does not have any instances. Eliminating this problem is quite straightforward; it just requires checking all leaf entities and verifying whether it contains any instances. In case of existence those entities should be removed or generalized or instances should be inserted.
4 Evaluation
4.1 Method
The ROD process was evaluated on Financial Instruments and Trading Strategies (FITS) ontology that is depicted in Figure 4.1.
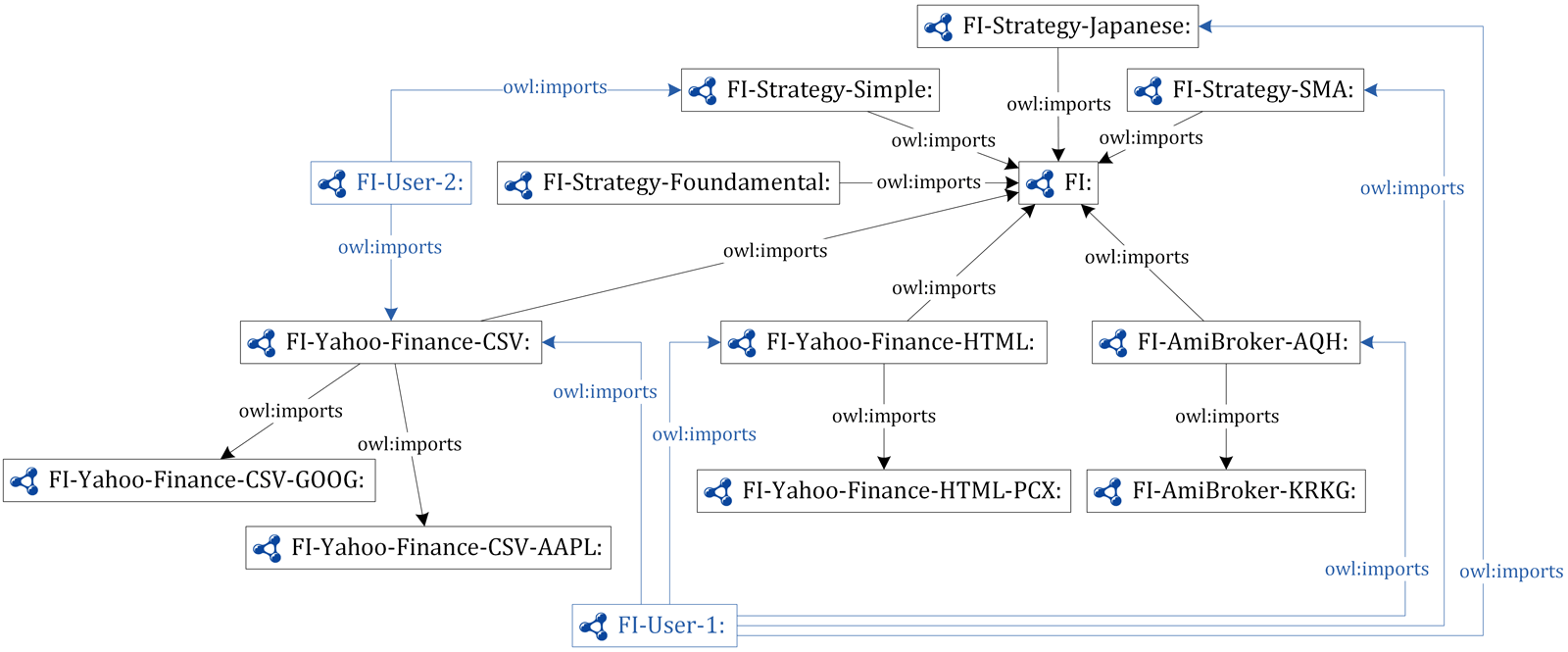
Figure 4.1: Financial instruments and trading strategies (FITS)
When building aforementioned ontology one of the requirements was to follow Semantic Web mantra of achieving as high level of reuse as possible. Therefore the main building blocks of FITS ontology are all common concepts about financial instruments. Furthermore every source of data (e.g., quotes from Yahoo! Finance in a form of CSV files and direct Web access, AmiBroker trading program format etc.) is encapsulated in a form of ontology and integrated into FITS ontology. Within every source of data developer can select which financial instrument is he interested in (e.g., GOOG, AAPL, PCX, KRKG etc.). The last and the most important component are financial trading strategies that developers can define. Every strategy was defined in its own ontology (e.g., FI-Strategy-Simple, FI-Strategy-SMA, FI-Strategy-Japanese etc.). The requirement was also to enable open integration of strategies, so developer can select best practices from several developers and add its own modification.
Two different approaches in constructing ontology and using it in aforementioned use case were used. The approach of rapid ontology development (ROD) was compared to ad-hoc approach to ontology development, which was based on existing methodologies CommonKADS, OTK and METHONTOLOGY. With ROD approach the proposed method was used with tools IntelliOnto and Protégé. The entire development process was monitored by iteration, where ontology completeness price and number of ontology elements (classes, properties and axioms with rules) were followed.
At the end the results included developed ontology, a functional component and information about the development process by iteration. The final version of ontology was reviewed by a domain expert, who confirmed adequateness. At implementation level ontology was expected to contain about \(250\) to \(350\) axioms of schematic part and numerous instances from various sources.
4.2 Results and Discussion
The process of ontology creation and exporting it as functional component was evaluated on FITS ontology and the results are depicted in Figures 4.2 and 4.3. Charts represent ontology completeness price and number of ontology elements regarding to iterations in the process.

Figure 4.2: OC assessment and number of ontology elements through iterations and phases of ROD process

Figure 4.3: OC assessment and number of ontology elements through iterations of ad-hoc development process
Comparing ROD to ad-hoc approach the following conclusions can be drawn:
- the number of iterations to develop required functional component using ROD approach \((30)\) is less than using ad-hoc approach \((37)\) which results in \(23\%\) less iterations;
- ontology developed with ROD approach is throughout the development process more complete and more appropriate for use than in ad-hoc, due to continuous evaluation and simultaneous alerts for developers.
During the process of ontology construction based on ROD approach the developer was continuously supported by ontology evaluation and recommendations for progressing to next steps. When developer entered a phase and started performing tasks associated with the phase, ontology completeness was evaluated as depicted in Figure 3.2. While OC was less than a threshold value, developer followed instructions for improving ontology as depicted in Figure 3.3. Results of OC evaluation are available in a simple view, where basic statistics about ontology is displayed (number of concepts, properties, rules, individuals etc.), progress bar depicting completeness, and details about evaluation, improvement recommendations and history of changes. The core element is progress bar that denotes how complete ontology is and is accompanied with a percentage value. Following are recommendations for ontology improvement and their gains (e.g., remove circulatory errors \((+10\%)\), describe concepts in natural language \((+8\%)\), connect concepts \((+7\%)\) etc.). When improvement is selected (e.g., remove circulatory errors) the details are displayed (gain, task and details). The improvement and planned actions are also clearly graphically depicted on radar chart (see Figure 3.2). The shaded area with strong border lines presents current situation, while red dot shows TO-BE situation if we follow selected improvement.
When OC price crosses a threshold value (in this experiment \(80\%\)) a recommendation to progress to a new phase is generated. We can see from our example that for instance recommendation to progress from phase 2.5 to phase 2.6 was generated in 20th iteration with OC value of \(91,3\%\), while in 19th iteration OC value was \(76,5\%\).
As Figure 4.2 depicts ontology completeness price and number of ontology elements are displayed. While progressing through steps and phases it’s seen that number of ontology elements constantly grow. On the other hand OC price fluctuate – it’s increasing till we reach the threshold to progress to next phase and decreases when entering new phase. Based on recommendations from the system, developer improves the ontology and OC price increases again. With introduction of OC steps in ontology development are constantly measured while enabling developers to focus on content and not technical details (e.g. language syntax, best modeling approach etc.).
5 Conclusions and Future work
Current methodologies and approaches for ontology development require very experienced users and developers, while we propose ROD approach that is more suitable for less technically oriented users. With constant evaluation of developed ontology that is introduced in this approach, developers get a tool for construction of ontologies with several advantages:
- the required technical knowledge for ontology modeling is decreased,
- the process of ontology modeling doesn’t end with the last successful iteration, but continues with post-development activities of using ontology as a functional component in several scenarios and
- continuous evaluation of developing ontology and recommendations for improvement.
In ontology evaluation several components are considered: description, partition, redundancy, consistency and anomaly. Description of ontology’s components is very important aspect mainly in early stages of ontology development and includes existence of entities, natural language descriptions and formal descriptions. This data is furthermore used for advanced axiom construction in latter stages. Partition errors deal with omitting important axioms and can be in a form of common classes, external instances, hierarchy of entities etc. Redundancy deals with multiple information being inferred more than once and includes identical formal definition and redundancy in hierarchy. With consistency the emphasis is on finding circulatory errors, while anomalies do not cause inaccurate reasoning about concepts, but point to badly designed areas in ontology. This includes checking for chain of inheritance, property clumps, lazy entities etc. It has been demonstrated on a case study from financial trading domain that a developer can build Semantic Web application for financial trading based on ontologies that consumes data from various sources and enable interoperability. The solution can easily be packed into a functional component and used in various systems.
The future work includes improvement of ontology completeness indicator by including more semantic checks and providing wider support for functional components and creating a plug-in for most widely used ontology editors for constant ontology evaluation. One of the planned improvements is also integration with popular social networks to enable developers rapid ontology development, based on reuse.
References
Allemang, Dean, and J. Hendler. 2008. Semantic Web for Working Ontologist: Effective Modeling in RDFS and OWL. Elsevier.
Avison, David, and Guy Fitzgerald. 2006. Information Systems Development: Methodologies, Techniques and Tools, 4th Edition. Maidenhead, UK: McGraw-Hill.
Bechhofer, S., and C. Goble. 2001. “Thesaurus Construction Through Knowledge Representation.” Data & Knowledge Engineering 37 (1): 25–45.
Beck, Kent, and Cynthia Andres. 2004. Extreme Programming Explained: Embrace Change, 2nd Edition. USA, Boston: Addison-Wesley.
Booch, Grady. 1993. Object Oriented Analysis and Design with Applications, 2nd Edition. Santa Clara, USA: Addison-Wesley.
Brambilla, Marco, Irene Celino, Stefano Ceri, and Dario Cerizza. 2006. “A Software Engineering Approach to Design and Development of Semantic Web Service Applications.” In 5th International Semantic Web Conference.
Brank, Janez, Marko Grobelnik, and Dunja Mladenić. 2005. A Survey of Ontology Evaluation Techniques.
Brewster, Christopher, Harith Alani, Srinandan Dasmahapatra, and Yorick Wilks. 2004. Data Driven Ontology Evaluation.
Cardoso, Jorge, Martin Hepp, and Miltiadis Lytras. 2007. The Semantic Web: Real World Applications from Industry. Springer.
Ciuksys, Donatas, and A. Caplinskas. 2007. “Reusing Ontological Knowledge About Business Process in IS Engineering: Process Configuration Problem.” Informatica 18 (4): 585–602.
Consortium, DSDM. 2005. DSDM Manual Version 4.2. UK, Surrey: Tesseract Publishing.
Corcho, O., M. Fernandez-Lopez, and A. Gomez-Perez. 2003. “Methodologies, Tools and Languages for Building Ontologies. Where Is Their Meeting Point?” Data & Knowledge Engineering 46 (1): 41–64.
Davies, John, Rudi Studer, and Paul Warren. 2006. Semantic Web Technologies - Trends and Research in Ontology-Based Systems. Chichester, England: John Wiley & Sons.
Dong, Y., and M. S. Li. 2004. “HyO-XTM: A Set of Hyper-Graph Operations on XML Topic Map Toward Knowledge Management.” Future Generation Computer Systems 20 (1): 81–100.
Dzemyda, Gintautas, and Leonidas Sakalauskas. 2009. “Optimization and Knowledge-Based Technologies.” Informatica 20 (2): 165–72.
Fahad, Muhammad, and Muhammad Abdul Quadir. 2008. “Ontological Errors - Inconsistency, Incompleteness and Redundancy.” In International Conference on Enterprise Information Systems (ICEIS) 2008.
Fernandez-Lopez, M., A. Gomez-Perez, J. P. Sierra, and A. P. Sierra. 1999. “Building a Chemical Ontology Using Methontology and the Ontology Design Environment.” Intelligent Systems 14 (1).
Gangemi, A., C. Catenacci, M. Ciaramita, and J. Lehmann. 2006. “Modelling Ontology Evaluation and Validation.” In 3nd European Semantic Web Conference (ESWC 2006), edited by Y. Domingue J. Sure, 140–54. Springer-Verlag Berlin.
Gómez-Pérez, Asunción. 1999. Evaluation of Taxonomic Knowledge in Ontologies and Knowledge Bases.
Hartmann, Jens, York Sure, Alain Giboin, Diana Maynard, Mari del Carmen Suárez-Figueroa, and Roberta Cuel. 2004. “D1.2.3 Methods for Ontology Evaluation.”
Heflin, J., and J. Hendler. 2000. “Searching the Web with SHOE.” In Artificial Intelligence for Web Search, 36–40. Menlo Park, USA: AAAI Press.
Jacobson, Ivar, Grady Booch, and James Rumbaugh. 1999. The Unified Software Development Process. Boston, USA: Addison-Wesley.
Jovanović, J., and D. Gašević. 2005. “Achieving Knowledge Interoperability: An XML/XSLT Approach.” Expert Systems with Applications 29 (3): 535–53.
Kesseler, M. 1996. “A Schema Based Approach to HTML Authoring.” World Wide Web Journal 96 (1).
Kotis, K., and G. Vouros. 2003. “Human Centered Ontology Management with HCONE.” In IJCAI ’03 Workshop on Ontologies and Distributed Systems.
Lozano-Tello, A., and Asunción Gómez-Pérez. 2004. “ONTOMETRIC: A Method to Choose the Appropriate Ontology.” Journal of Database Management 15 (2): 1–18.
Maedche, Alexander, and S. Staab. 2002. Measuring Similarity Between Ontologies.
Magdalenic, Ivan, Danijel Radosevic, and Zoran Skocir. 2009. “Dynamic Generation of Web Services for Data Retrieval Using Ontology.” Informatica 20 (3): 397–416.
Martin, James. 1991. Rapid Application Development. Indianapolis, USA: MacMillan Publishing.
Martin, James, and C. Finkelstein. 1981. Information Engineering. Vol. Volume 1 and 2. New Jersey, USA: Prentice Hall.
Miller, George A. 1995. “WordNet: A Lexical Database for English.” Communications of the ACM 38 (11): 39–41.
Mylopoulos, J. 1998. “Information Modeling in the Time of the Revolution.” Information Systems 23 (3-4): 127–55.
Nicola, A. D., R. Navigli, and M. Missikoff. 2005. “Building an eProcurement Ontology with UPON Methodology.” In 15th E-Challenges Conference. Ljubljana, Slovenia.
Noy, Natalya F., Ramanathan Guha, and M. A. Musen. 2005. User Ratings of Ontologies: Who Will Rate the Raters?
Park, Jack, and Sam Hunting. 2002. XML Topic Maps: Creating and Using Topic Maps for the Web. Boston, USA: Addison-Wesley.
Porzel, Robert, and Rainer Malaka. 2004. A Task-Based Approach for Ontology Evaluation.
SanJuan, E., and F. Ibekwe-SanJuan. 2006. “Text Mining Without Document Context.” Information Processing & Management 42 (6): 1532–52.
Schreiber, G., H. Akkermans, A. Anjewierden, R. de Hoog, N. Shadbolt, W. van de Velde, and B. Wielinga. 1999. Knowledge Engineering and Management - the CommonKADS Methodology. London, England: The MIT Press: Cambridge, Massachusetts.
Smaizys, Aidas, and Olegas Vasilecas. 2009. “Business Rules Based Agile ERP Systems Development.” Informatica 20 (3): 439–60.
Staab, S., C. Braun, I. Bruder, A. Duesterhoeft, A. Heuer, M. Klettke, G. Neumann, et al. 1999. “A System for Facilitating and Enhancing Web Search.” In International Working Conference on Artificial and Natural Neural Networks: Engineering Applications of Bio-Inspired Artificial Neural Networks (IWANN ’99).
Sure, York. 2003. “Methodology, Tools & Case Studies for Ontology Based Knowledge Management.” PhD Thesis.
Uschold, M., and M. Grueninger. 1996. “Ontologies: Principles, Methods and Applications.” Knowledge Sharing and Review 11 (2).
Uschold, M., and M. King. 1995. “Towards a Methodology for Building Ontologies.” In Workshop on Basic Ontological Issues in Knowledge Sharing (IJCAI ’95).
Vasilecas, Olegas, and Sergejus Sosunovas. 2008. “Practical Application of BRTL Approach for Financial Reporting Domain.” Information Technology and Control 37 (2): 106–13.
Vasilecas, Olegas, Diana Kalibatiene, and Giancarlo Guizzardi. 2009. “Towards a Formal Method for Transforming Ontology Axioms to Application Domain Rules.” Information Technology and Control 38 (4): 271–82.
Veale, Tony. 2006. “An Analogy-Oriented Type Hierarchy for Linguistic Creativity.” Knowledge-Based Systems 19 (7): 471–79.
Waterson, A., and A. Preece. 1999. “Verifying Ontological Commitment in Knowledge-Based Systems.” Knowledge-Based Systems 12 (1-2): 45–54.
Wiederhold, G. 1992. “Mediators in the Architecture of Future Information Systems.” IEEE Computer 25 (3): 38–49.